ChatGPT의 고급 기능들, 예를 들어 코드 디버깅, 글쓰기 또는 농담하기 등은 그 인기를 폭발시켰습니다. 그러나 그 도움은 텍스트에만 국한되어 왔습니다 - 그러나 이제는 그것이 변화하려 합니다.
화요일에 OpenAI가 GPT-4를 공개했습니다. 이는 텍스트와 이미지 입력을 모두 허용하고 텍스트를 출력하는 큰 멀티모달 모델입니다.
또한: ChatGPT가 정보 출처와 인용을 제공하는 방법
일상 대화에서 GPT-3.5와 GPT-4의 차이는 "미묘"할 것입니다. 그러나 새로운 모델은 신뢰성, 창의성, 심지어 지능 측면에서 훨씬 더 능력이 향상될 것입니다.
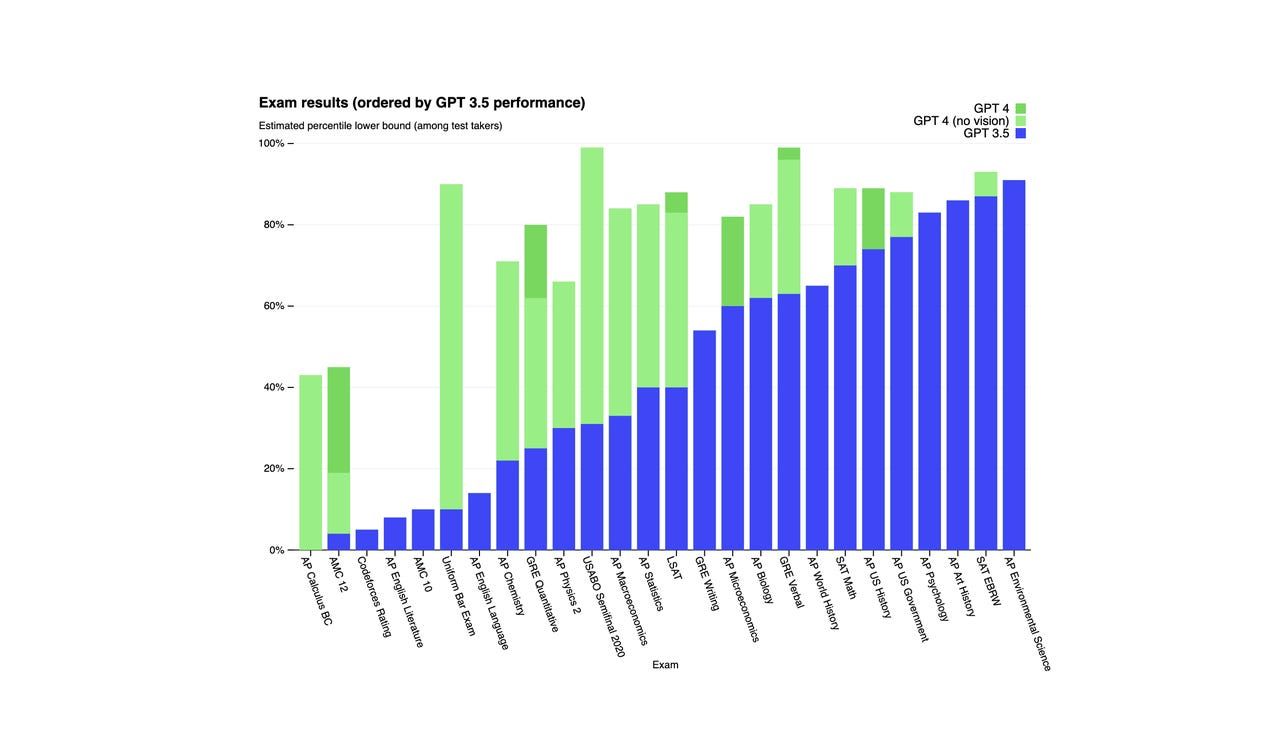
OpenAI에 따르면, GPT-4는 시뮬레이션된 주문식 시험의 상위 10%에 들었으며, GPT-3.5는 하위 10% 정도의 점수를 받았습니다. 아래의 그래프에서 볼 수 있는 것처럼, GPT-4는 또한 벤치마크 테스트에서 GPT-3.5보다 성과가 뛰어났습니다.

문맥을 알려드리면, ChatGPT는 3.5 시리즈의 모델에서 파인튜닝 된 언어 모델 위에서 작동하여, 챗봇이 텍스트 출력으로 제한된다는 점입니다.
지난 주에 마이크로소프트 독일의 CTO인 안드레아스 브라운이 연설한 후 OpenAI의 GPT-4 발표가 있었습니다. 그는 GPT-4가 곧 출시될 것이며 텍스트에서 비디오 생성이 가능할 것이라고 말했습니다.
"다음 주에 GPT-4를 소개할 것입니다. 그곳에서는 완전히 다른 가능성을 제공하는 다중 모달 모델이 있을 것입니다 - 예를 들어, 비디오,"라고 Braun은 행사에서 Heise, 독일 언론 매체에 말했습니다.
GPT-4가 멀티모달인 것에도 불구하고, 텍스트에서 비디오로 변환 가능한 생성기에 대한 주장은 조금 부정확했습니다. 이 모델은 아직 동영상을 생성할 수는 없지만, 시각적인 입력은 받을 수 있으며 이는 이전 모델과 큰 차이점입니다.
OpenAI가 이 기능을 자랑으로 제시한 예 중 하나는 사용자의 입력에 따라 ChatGPT가 이미지를 스캔하여 사진이 왜 웃긴지 파악하려는 시도를 하는 것을 보여줍니다.
다른 예시로는 그래프 이미지를 업로드하여 GPT-4에게 계산을 요청하거나 문제를 해결하도록 워크시트를 업로드하는 것이 포함됩니다.
또한: ChatGPT가 에세이 작성에 도움을 줄 수 있는 5가지 방법
OpenAI는 GPT-4의 텍스트 입력 기능을 ChatGPT 및 API를 통해 대기 목록을 통해 공개 할 것이라고 말합니다. 이미지 입력 기능은 OpenAI가 시작하도록 유일한 파트너와 협력하고 있어서 조금 길게 기다려야 할 것입니다.
텍스트에서 동영상을 생성하는 기능이 없어 실망스러우시더라도 걱정하지 마세요, 이는 완전히 새로운 개념은 아닙니다. Meta와 Google과 같은 기술 기업들은 이미 해당 기능에 대한 모델을 개발 중입니다. Meta는 Make-A-Video를, Google은 Imagen Video를 사용하여 사용자 입력을 기반으로 동영상을 생성하는 인공지능을 활용합니다.